GLM-5 vs Claude Opus 4.6 2026: Chọn AI coding đúng cho team Việt
- Danh mục
- Blog
- Ngày đăng
- 18 tháng 4, 2026
- Thời gian đọc
- 14 phút
- Chủ đề chính
- GLM-5 vs Claude Opus 4.6 — so sánh chất lượng code, chi phí API, bảo mật, latency và checklist pilot 14 ngày cho team dev Việt.
GLM-5 vs Claude Opus 4.6 2026: Chọn AI coding đúng cho team Việt

Vì sao team dev Việt dễ chọn sai AI coding (và trả giá bằng chi phí ẩn)?
Phần lớn team chọn AI coding theo 3 tín hiệu “đẹp” nhưng dễ sai:
- Demo viết function rất nhanh
- Leader thấy benchmark tổng quát trên mạng cao
- Sales báo giá token “có vẻ rẻ”
Vấn đề là khi đưa vào repo thật, chi phí ẩn mới xuất hiện:
- Test fail tăng: PR merge nhanh hơn nhưng số bug lọt qua CI tăng.
- Token bill vượt dự toán: prompt dài + loop sửa lỗi khiến lượng token nở mạnh theo tuần.
- Tích hợp chậm: tool tốt ở chat, nhưng không ổn trong Git hook, PR template, hoặc pipeline CI/CD.
- Năng suất “ảo”: dev junior giao code nhiều hơn nhưng reviewer senior mất thời gian gấp đôi.
- Khóa nhà cung cấp (lock-in): prompt, toolchain, guardrail gắn cứng vào 1 model.
Vì vậy, thay vì hỏi “model nào xịn hơn?”, team nên hỏi:
- Pass@k cho task nội bộ là bao nhiêu?
- Regression bug sau 7 ngày là bao nhiêu?
- Chi phí/1.000 tác vụ thực tế là bao nhiêu?
- MTTR (mean time to resolve) khi debug có giảm không?
Nếu bạn chưa có baseline đa mô hình, xem thêm benchmark tiếng Việt tại bài GPT-5.4 vs Gemini 3.1 Pro vs Claude Opus 4.6 vs Grok 4: Benchmark Tiếng Việt 2026 để có góc nhìn rộng trước khi chốt stack coding.
GLM-5 và Claude Opus 4.6 là gì trong bối cảnh AI coding 2026?
GLM-5: thiên về hiệu quả chi phí và độ linh hoạt triển khai
Trong bối cảnh 2026, GLM-5 thường được team quan tâm khi cần:
- Chi phí inference thấp hơn ở khối lượng lớn
- Dễ thử nghiệm routing nhiều tác vụ khác nhau
- Khả năng tùy biến prompt theo workflow nội bộ
Phù hợp với đội muốn tối ưu unit economics (chi phí trên mỗi ticket đóng).
Claude Opus 4.6: thiên về chất lượng reasoning và ổn định output
Claude Opus 4.6 thường nổi bật ở:
- Lập luận sâu với codebase lớn
- Giải thích refactor và trade-off rõ
- Tỷ lệ “đúng ngay lần đầu” cao hơn ở tác vụ phức tạp
Phù hợp với team ưu tiên giảm rework ở tầng thiết kế, architecture notes, và review logic nghiệp vụ.
Bối cảnh đội kỹ thuật Việt cần lưu ý
Team Việt thường có đặc thù:
- Yêu cầu song ngữ (spec tiếng Việt, code/comment tiếng Anh)
- Legacy stack pha trộn (PHP/Java/.NET + service mới Node/Python)
- Deadline release gắt theo sprint ngắn
Do đó, chọn model chỉ theo benchmark coding public là chưa đủ. Cần kiểm tra khả năng xử lý tài liệu nội bộ tiếng Việt, độ ổn định trong PR review, và hành vi khi prompt “nửa kỹ thuật nửa nghiệp vụ”.
So sánh năng lực coding cốt lõi: viết mới, refactor, debug và đọc codebase lớn
1) Viết mới tính năng (greenfield module)
Prompt mẫu để benchmark:
Bạn là senior backend.
Stack: Node.js + PostgreSQL.
Yêu cầu: tạo module quản lý coupon gồm:
- API tạo/sửa/xóa coupon
- Rule thời gian + số lượt dùng + whitelist user tier
- Unit test (Jest) tối thiểu 12 case
- Migration SQL
Output: code + test + checklist bảo mật.Tiêu chí chấm:
- Compile pass
- Test pass lần đầu
- Đủ edge case
- Không để lộ lỗ hổng obvious (SQL injection, race condition)
2) Refactor code legacy
Prompt mẫu:
Refactor đoạn service này theo clean architecture.
Giữ nguyên behavior hiện tại.
Giảm duplicate logic validate.
Thêm test bảo toàn hành vi cũ.Tiêu chí chấm:
- Giảm độ phức tạp cyclomatic
- Không vỡ backward compatibility
- Reviewer đọc dễ hơn (subjective score 1-5)
3) Debug production issue
Prompt mẫu:
Dựa trên log + stack trace dưới đây, đề xuất 3 giả thuyết nguyên nhân.
Ưu tiên nguyên nhân có xác suất cao nhất.
Đưa patch tối thiểu + plan rollback.Tiêu chí chấm:
- Đúng root cause
- Patch ít thay đổi nhưng hiệu quả
- Có runbook rollback rõ
4) Đọc codebase lớn và tạo bản đồ phụ thuộc
Prompt mẫu:
Đọc cấu trúc repo (đính kèm tree + 10 file chính).
Vẽ dependency map giữa module billing, auth, order.
Chỉ ra điểm coupling cao và đề xuất tách dần trong 2 sprint.Tiêu chí chấm:
- Nhận diện đúng dependency nóng
- Đề xuất tách có tính khả thi theo sprint
- Không “đập đi làm lại” thiếu thực tế
Khung đo pass@k và regression bug
- pass@1: model cho ra lời giải đúng ngay lần đầu
- pass@3: có đúng trong 3 lần thử không
- Regression bug rate: số bug mới sinh ra sau refactor / tổng ticket refactor
- Review overhead: phút review trung bình / PR
Gợi ý: benchmark tối thiểu 40–60 task thật từ backlog, chia đều 4 nhóm tác vụ trên.
Bảng so sánh GLM-5 vs Claude Opus 4.6: chất lượng, chi phí, latency và TCO
Bảng đối chiếu nhanh theo KPI vận hành
| Tiêu chí | GLM-5 | Claude Opus 4.6 | Tốt hơn (tham chiếu) |
|---|---|---|---|
| Chất lượng code task đơn giản | Tốt | Tốt | Ngang nhau (task cơ bản) |
| Chất lượng code task phức tạp (multi-file reasoning) | Khá–Tốt | Tốt–Rất tốt | Claude Opus 4.6 |
| Tỷ lệ pass@1 nội bộ | % | % | Phụ thuộc repo |
| Regression bug sau refactor | % | % | Cần pilot |
| Context window tối đa | tokens | tokens | |
| Latency trung vị (API) | ms | ms | |
| Độ ổn định output giữa các lần chạy | Trung bình–Tốt | Tốt | Claude Opus 4.6 |
| Chi phí input token | USD/1M | USD/1M | |
| Chi phí output token | USD/1M | USD/1M | |
| Chi phí 1.000 tác vụ coding chuẩn hóa | USD | USD | |
| TCO 3 tháng (team 8 dev) | USD | USD | Tùy routing |
| Mức phù hợp mô hình single-vendor | Tốt | Tốt | Ngang |
| Mức phù hợp multi-model strategy | Tốt | Tốt | Ngang |
Giá cả và gói sử dụng (tham khảo triển khai)
Lưu ý: toàn bộ thông số cần kiểm tra lại trên trang chính thức trước khi mua.
| Hạng mục giá | GLM-5 | Claude Opus 4.6 |
|---|---|---|
| Free tier | Có/Không | Có/Không |
| Gói dev cá nhân | USD/tháng | USD/tháng |
| Gói team | USD/user/tháng | USD/user/tháng |
| API pay-as-you-go | ||
| Enterprise/SLA | Có | Có |
| Discount theo volume | Có | Có |
Công thức tính chi phí mỗi 1.000 tác vụ
Bạn có thể dùng công thức:
Chi phí = (Input token trung bình * giá input + Output token trung bình * giá output) * 1.000
Sau đó cộng thêm:
- Chi phí retry do timeout/lỗi format
- Chi phí review thủ công
- Chi phí bugfix sau merge
Đây mới là TCO thực, không phải giá token thuần.
Tiếng Việt, tài liệu nội bộ và workflow developer: mô hình nào hợp team Việt hơn?
Xử lý yêu cầu song ngữ
Với team Việt, prompt thực tế thường dạng:
- Business rule tiếng Việt
- Code/comment tiếng Anh
- Ticket Jira viết nửa Việt nửa Anh
Điểm cần test:
- Model có hiểu đúng sắc thái nghiệp vụ tiếng Việt không?
- Có tự “dịch sai” điều kiện biên khi chuyển sang code không?
- Có giữ nhất quán thuật ngữ xuyên suốt PR không?
Đọc wiki nội bộ và tài liệu rời rạc
Nhiều công ty có tài liệu:
- Notion cũ + Google Docs + README thiếu đồng bộ
- Naming convention không thống nhất
- Rule nghiệp vụ nằm trong chat/meeting note
Model tốt cho team Việt không chỉ “viết code hay”, mà phải tóm tắt đúng quy ước nội bộ và nhắc lại rule khi sinh code/test.
Bạn có thể tham chiếu thêm cách dùng Claude trong workflow thực tế tại bài Hướng dẫn dùng Claude AI từ A đến Z cho người mới (2026), rồi áp vào bối cảnh team kỹ thuật thay vì người dùng phổ thông.
Ổn định trong Git, PR review và CI/CD
Checklist cần kiểm tra:
- Tạo commit message đúng chuẩn team
- Sinh PR description có risk note + rollback plan
- Không phá format lint/test pipeline
- Khi CI fail, model sửa đúng lỗi thay vì sửa lan
Nếu team đang chuẩn hóa tự động hóa pipeline, xem thêm tư duy tích hợp tại Workflow Tự Động AI 2026: Zapier vs n8n vs Activepieces Cho SME Việt để thiết kế luồng “AI đề xuất + rule engine kiểm tra” thay vì để model quyết định 100%.
Bảo mật, tuân thủ và rủi ro lock-in khi triển khai vào sản phẩm thật
Các điểm bảo mật cần so sánh trực diện
| Hạng mục | GLM-5 | Claude Opus 4.6 | Ghi chú |
|---|---|---|---|
| Dữ liệu API có dùng để train mặc định? | Bắt buộc xác nhận hợp đồng | ||
| Data retention mặc định | ngày | ngày | Cần policy rõ theo môi trường |
| Vùng lưu trữ dữ liệu | Liên quan yêu cầu pháp lý | ||
| Audit log truy cập | Có | Có | Cần export được |
| RBAC/SSO/SCIM | Có | Có | Quan trọng với team > 20 user |
| SLA uptime enterprise | % | % | Gắn điều khoản bồi thường |
Kiến trúc giảm phụ thuộc nhà cung cấp (anti lock-in)
Khuyến nghị kiến trúc 3 lớp:
-
Model Gateway Layer Chuẩn hóa API gọi model qua một interface nội bộ (không gọi thẳng từng vendor trong business code).
-
Prompt & Policy Layer Lưu prompt versioned trong repo riêng; tách prompt khỏi ứng dụng.
-
Evaluation Layer Bộ benchmark nội bộ chạy định kỳ (tuần/tháng) để phát hiện drift chất lượng và quyết định reroute model.
Với cách này, đổi model sẽ là cấu hình/routing, không phải refactor cả sản phẩm.
Kịch bản chọn mô hình theo từng loại đội ngũ: startup, outsourcing, product company
Startup (ưu tiên tốc độ + runway)
- Ngân sách AI tháng: ** triệu VNĐ**
- Mục tiêu: ra MVP nhanh, chấp nhận chỉnh sửa thủ công
- Khuyến nghị: bắt đầu 1 model chính + 1 model dự phòng cho task khó
Outsourcing (ưu tiên biên lợi nhuận + SLA dự án)
- Ngân sách AI tháng: ** triệu VNĐ** theo số dự án active
- Mục tiêu: dự đoán được chi phí/ticket, đảm bảo deadline
- Khuyến nghị: routing theo loại task (task đơn giản dùng model rẻ hơn, task phức tạp chuyển model mạnh hơn)
Product company (ưu tiên chất lượng dài hạn + governance)
- Ngân sách AI tháng: ** triệu VNĐ** trở lên
- Mục tiêu: giảm bug regression, chuẩn hóa engineering process
- Khuyến nghị: multi-model có benchmark chuẩn, audit log đầy đủ, chính sách dữ liệu nghiêm ngặt
Bảng Ưu/Nhược: chọn 1 model hay đa model
| Chiến lược | Ưu điểm | Nhược điểm | Phù hợp khi |
|---|---|---|---|
| Single model | Vận hành đơn giản, dễ training team | Rủi ro lock-in, khó tối ưu chi phí theo task | Team nhỏ, quy trình chưa ổn định |
| Multi-model | Tối ưu chất lượng/chi phí theo workload, giảm phụ thuộc vendor | Phức tạp tích hợp, cần gateway + observability | Team trung bình-lớn, có DevOps/MLOps |
Nếu còn phân vân giữa nhiều hệ model, bạn có thể đối chiếu thêm góc nhìn rộng ở bài ChatGPT, Claude hay Gemini 2026: Nên trả tiền cho tool nào?.
Checklist pilot 14 ngày để tự ra quyết định cho team dev
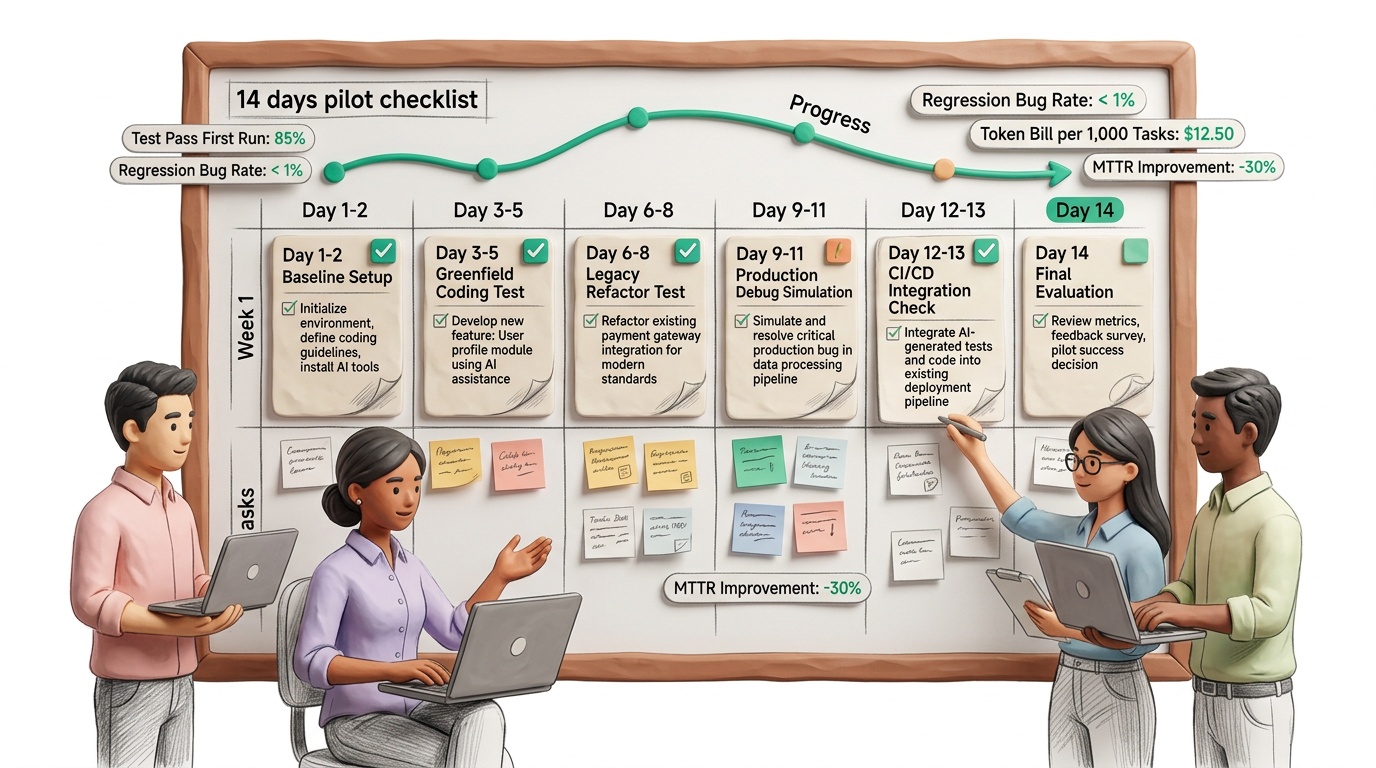
5 KPI cố định (không đổi trong suốt pilot)
- pass@1 trên bộ task chuẩn
- Regression bug rate sau merge 7 ngày
- Cycle time PR (tạo PR → merge)
- Chi phí/1 ticket đóng
- Mức hài lòng reviewer (thang 1–5)
Lộ trình 14 ngày đề xuất
| Ngày | Việc cần làm | Output bắt buộc |
|---|---|---|
| 1 | Chốt phạm vi pilot, chọn 40–60 task thật | Danh sách task + owner |
| 2 | Thiết kế prompt chuẩn theo 4 nhóm tác vụ | Prompt pack v1 |
| 3 | Thiết lập logging token, latency, retry | Dashboard tracking |
| 4 | Chạy baseline với GLM-5 | Báo cáo KPI ngày |
| 5 | Chạy baseline với Claude Opus 4.6 | Báo cáo KPI ngày |
| 6 | So sánh pass@1/pass@3 theo task | Bảng so sánh v1 |
| 7 | Kiểm tra regression từ code đã merge | Báo cáo bug tuần |
| 8 | Tối ưu prompt vòng 2 cho cả 2 model | Prompt pack v2 |
| 9 | Chạy lại benchmark có kiểm soát | KPI delta |
| 10 | Test tình huống xấu: context dài, log nhiễu | Báo cáo độ ổn định |
| 11 | Đo hiệu suất reviewer + cycle time PR | Báo cáo năng suất |
| 12 | Tính TCO 1.000 tác vụ + dự phóng 3 tháng | Bảng chi phí |
| 13 | Workshop kỹ thuật: chốt rủi ro bảo mật/lock-in | Risk register |
| 14 | Go/No-Go và kế hoạch rollout | Quyết định chính thức |
Scorecard chấm điểm (100 điểm)
- Chất lượng code: 35 điểm
- Chi phí thực tế: 25 điểm
- Tốc độ/latency: 15 điểm
- Tích hợp workflow: 15 điểm
- Bảo mật/tuân thủ: 10 điểm
Ngưỡng pass đề xuất:
- Tổng điểm ≥ 75
- Không KPI nào dưới 60%
- Regression bug không vượt ngưỡng nội bộ
Nếu không đạt, không ký enterprise ngay — kéo dài pilot thêm 2 tuần với tập task khó hơn.
Câu hỏi thường gặp
GLM-5 hoặc Claude Opus 4.6 có gói miễn phí không?
Có thể có/không tùy thời điểm và khu vực phát hành, cần kiểm tra trực tiếp trang giá chính thức: ****.
Hai mô hình khác biệt lớn nhất ở điểm nào?
Thường khác ở độ ổn định reasoning cho task phức tạp và chi phí/token thực tế khi chạy ở quy mô lớn: ****.
Team nhỏ 5–7 dev có cần multi-model ngay không?
Chưa cần ngay. Bắt đầu 1 model chính, nhưng thiết kế gateway từ đầu để sau này chuyển multi-model không phải viết lại hệ thống.
Ước tính ngân sách triển khai ban đầu thế nào?
Lấy:
- Số ticket/tháng
- Token trung bình/ticket
- Tỷ lệ retry
- Thời gian review bổ sung => tính ra chi phí tối thiểu + 20–30% buffer: ****.
Kết luận: nên chọn GLM-5 hay Claude Opus 4.6 cho team dev Việt?
Nếu team bạn ưu tiên tối ưu chi phí theo khối lượng lớn và chấp nhận đầu tư thêm vào kiểm soát chất lượng, GLM-5 có thể là hướng hợp lý để pilot trước. Nếu team ưu tiên độ chắc chắn ở task phức tạp, giảm vòng review/refactor lại, Claude Opus 4.6 thường là lựa chọn an toàn hơn.
Điểm mấu chốt: đừng chốt theo hype. Hãy chốt theo KPI nội bộ, TCO thật và rủi ro lock-in.
Bước tiếp theo:
- Bắt đầu pilot từ trang công cụ: /go/[tool-slug]
- Xem thêm danh mục công cụ AI: /cong-cu-ai/
- Đọc thêm bài phân tích chuyên sâu khác: /blog